
























应用市场
悟空应用市场与生态伙伴通过产品级融合,为客户提供全面、专业、领先的产品及解决方案,共建产业互联。
前往应用市场 >

Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion
J Tian, L Aggarwal, A Colaco, Z Kira, M Gonzalez-Franco
[Georgia Institute of Technology & Google]
扩散、关注和分割:基于Stable Diffusion的无监督零样本分割
提出DiffSeg,一种无监督零样本分割方法,仅使用预训练的stable diffusion模型,不需要任何训练数据或其他外部信息。
利用stable diffusion模型中的自注意力层,其中包含以4D注意力张量的形式存在的内在对象分组信息。
观察到注意力张量中存在两个属性:Intra-Attention Similarity(注意力图中的位置倾向于对属于同一对象的位置激活)和Inter-Attention Similarity(属于同一对象的不同位置对应的注意力图倾向于相似)。
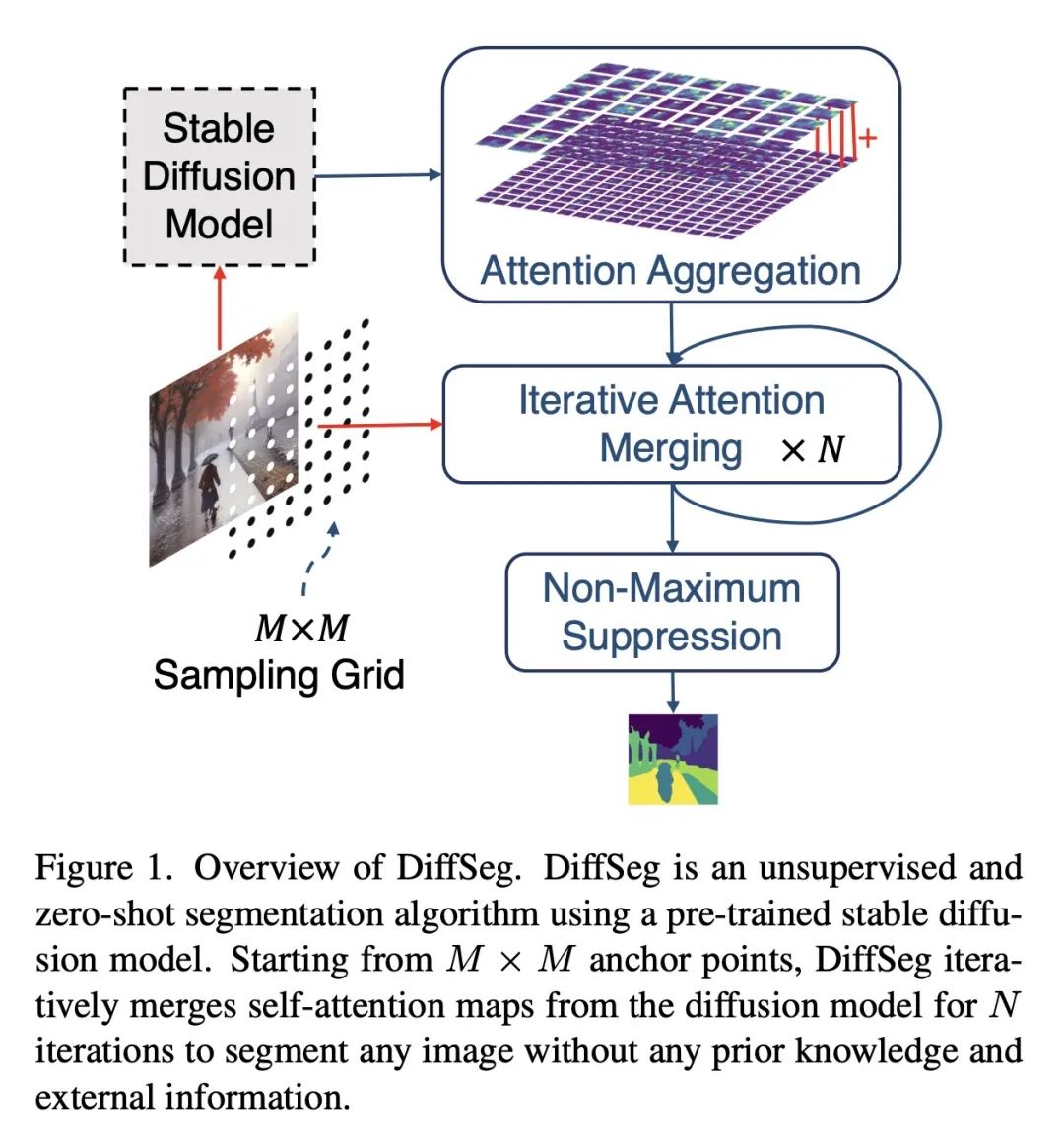
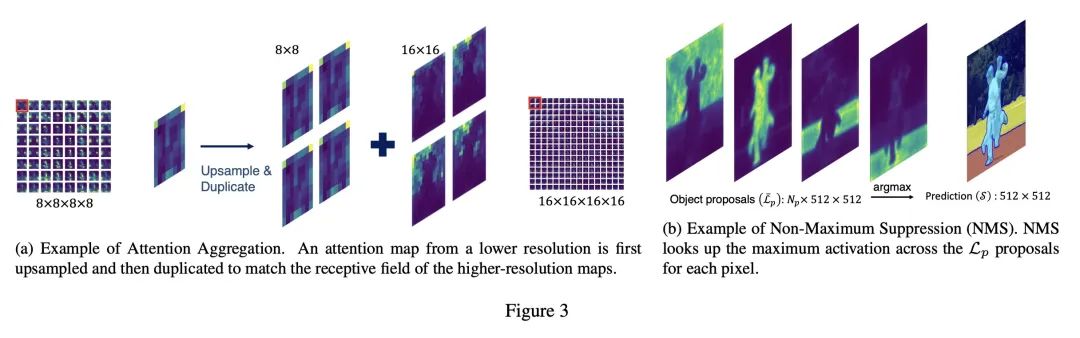
DiffSeg由3个主要步骤组成:注意力聚合、迭代注意力合并和非最大抑制,它聚合多分辨率的注意力图,基于KL散度迭代合并注意力图,并将合并后的图转换为分割掩码。
在COCO-Stuff和Cityscapes上实现了无监督零样本分割的最新水准效果,明显优于之前的工作。
自注意力层在没有任何分割标签的无监督条件下训练,但包含如此强大的对象分组信息,可以提取出来进行高质量分割。
限制包括在Cityscapes等专门数据集上的小目标性能较差,依赖预训练模型的泛化能力,以及计算复杂度。
动机:解决无监督和零样本分割的挑战,以便在没有任何标注或先验知识的情况下对任何图像进行分割。
方法:提出一种基于stable diffusion模型的后处理方法,称为DiffSeg。该方法利用扩散模型生成的自注意力张量来生成分割掩码。DiffSeg包括三个主要组件:注意力聚合、迭代注意力合并和非最大抑制。
优势:DiffSeg不需要任何训练或语言依赖,能为任何图像提取高质量的分割掩码。在COCO-Stuff-27数据集上,DiffSeg在像素准确度和平均IoU方面超过了之前的无监督零样本方法。
一句话总结: 提出一种无监督和零样本的分割方法DiffSeg,利用稳定扩散模型中的自注意力张量生成高质量的分割掩码。
https://arxiv.org/abs/2308.12469
悟空CRM产品更多介绍:www.5kcrm.com















 豫公网安备 41010702002713号
豫公网安备 41010702002713号




