
























应用市场
悟空应用市场与生态伙伴通过产品级融合,为客户提供全面、专业、领先的产品及解决方案,共建产业互联。
前往应用市场 >

前言
在AI盛行的当下,文本生成领域由ChatGPT独领风骚,文生图领域的头部则要数Midjourney和Stable Diffusion了。本文的主旨是向大家介绍Stable Diffusion的原理,后续会推出几期Stable Diffusion相关的干货分享,敬请期待。
在开始正文之前向大家推荐一款笔者觉得整体体验还不错的MJ画图网站,对于机器配置不高又想要尝试AI画图的同学可以自行前往一观,可以扫描下面的AI二维码,也可以查看知识库。知识库链接为:
https://xab7u5dx7i4.feishu.cn/docx/H7DqduzhkojzEXxfNFWcSVH4nzf

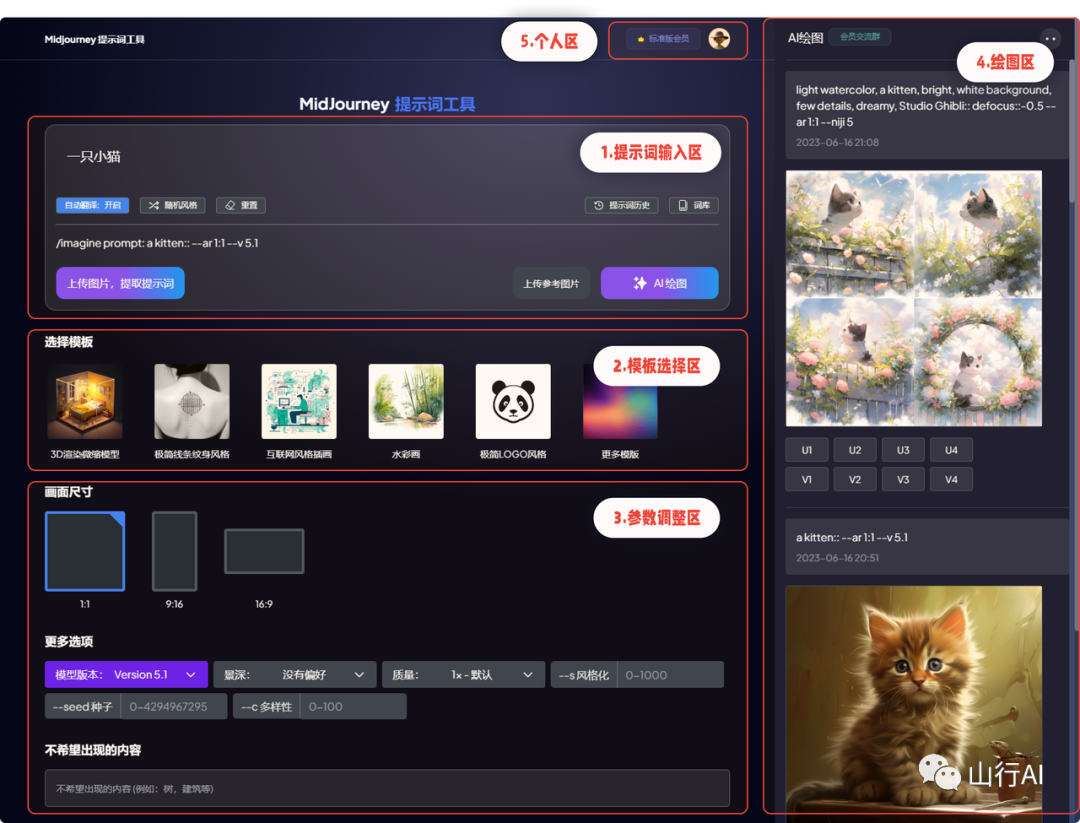
可以扫描上面的AI二维码进入,绘图界面如下:
Stable Diffusion(稳定扩散)的原理解释
稳定扩散如何工作?解释文本到图像生成背后的技术。

(用户定义文本提示用于文本到图像合成)
大型文本到图像模型在实现高质量的图像合成方面取得了显著成功。扩散模型可应用于文本到图像生成任务,以实现最先进的图像生成结果。稳定扩散模型在图像生成方面取得了最先进的结果。稳定扩散是基于一种特殊的扩散模型,被称为潜在扩散模型,该模型在《使用潜在扩散模型进行高分辨率图像合成》(https://arxiv.org/abs/2112.10752)中提出并由来自[CompVis](https://github.com/CompVis)、[LMU](https://ommer-lab.com/)和[RunwayML](https://runwayml.com/)的研究人员和工程师创建。该模型最初是在[LAION-5B](https://laion.ai/blog/laion-5b/)数据库的512x512图像子集上进行训练的。这一点尤其可以通过使用预训练语言模型如CLIP将文本输入编码成潜在向量来实现。扩散模型可以通过从文字生成图像数据来实现最先进的结果。但在生成高分辨率图像时,去噪的过程非常缓慢并且消耗大量内存。因此,对于训练这些模型并且在推断中使用它们来说具有挑战性。在这方面,通过将扩散过程应用于较低维度的“潜在”空间,而不是使用实际的像素空间,潜在扩散可以减少内存和计算时间。在潜在扩散中,模型被训练以生成图像的潜在(压缩)表示。
扩散模型的训练 稳定扩散是一个在数十亿张图片上训练得到的大型文本到图像扩散模型。图像扩散模型学习去噪生成输出图片。稳定扩散使用从训练数据编码而来的潜在图像作为输入。此外,给定一个初始图像zo,扩散算法逐渐向图像添加噪声并生成带有噪声的图片zt,t表示添加噪声的次数。当t足够大时,图片逼近纯噪声。给定一组输入,如时间步长t、文本提示和图像扩散算法,学习网络来预测添加到带噪声图像zt的噪声。潜在扩散主要由三个主要组件组成:
1.自编码器(VAE)。2.U-Net。3.文本编码器,例如CLIP的文本编码器。
1. 自编码器(VAE)
VAE模型由编码器和解码器两个部分组成。在潜在扩散训练过程中,编码器将512的图像转换为大小为64的低维潜在图像表示,用于正向扩散过程。我们将这些编码版本的图像称为潜在变量。在训练的每个步骤中,我们对这些潜在变量应用越来越多的噪声。这些编码的潜在图像表示作为输入传递给U-Net模型。在这里,我们将一个形状为(3, 512, 512)的图像转化为一个形状为(4, 64, 64)的潜在因子,这样可以节省48倍的内存。与像素空间扩散模型相比,这样可以降低内存和计算需求。因此,在16GB Colab GPU上,我们能够非常快速地生成512 × 512的图像。解码器将潜在因子重新转换为图像。我们使用VAE解码器将逆扩散过程生成的去噪潜在因子转化为图像。在推断过程中,我们只需要使用VAE解码器将去噪图像转化为实际图像。

2. UNet
U-Net用于预测去噪后的图像表示,输入为有噪声的潜在向量。UNet的输出是潜在向量中的噪声。通过将噪声从有噪声的潜在向量中减去,我们能够得到实际的潜在向量。输入噪声潜变量(x)并预测噪声的Unet。我们使用一个条件模型,该模型还需要输入时间步长(t)和文本嵌入作为指导。
因此,该模型如下所示:

该模型本质上是一个具有编码器(12个块)、中间块和跳过连接解码器(12个块)的UNet。在这25个块中,有8个块是下采样或上采样卷积层,而17个块是主要块,每个块都包含四个ResNet层和两个视觉Transformer(ViTs)。在这里,编码器将图像表示压缩为较低分辨率的图像表示,而解码器将较低分辨率的图像表示解码回原始的高分辨率图像表示,该图像表示应该更少带有噪音。
3. 文本编码器 文本编码器将输入提示转换为嵌入空间,作为输入传递给U-Net。这作为对噪声潜变量的指导,当我们训练U-Net进行去噪处理时。文本编码器通常是一个简单的基于变换器的编码器,将一系列输入标记映射到一系列潜在文本嵌入。稳定扩散不会训练新的文本编码器,而是使用已经训练好的文本编码器CLIP。文本编码器创建与输入文本相对应的嵌入。
分词

输出嵌入输出嵌入

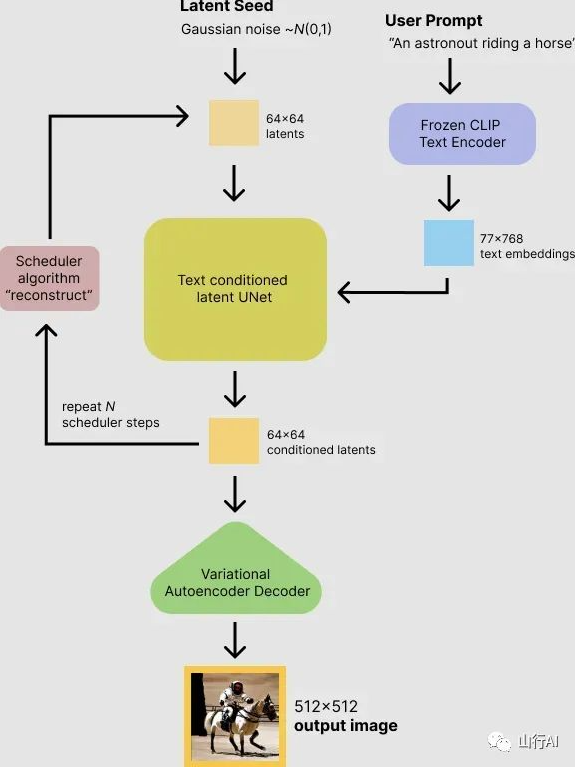
(稳定扩散推理过程)
调度器
除了以上三种之外,还有一个调度器,用于向图像添加噪声,然后使用模型预测噪声。
from diffusers import LMSDiscreteScheduler scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
上述设置了一个用于训练模型的调度程序。如果我们想为较少的步骤设置调度程序,我们可以按照以下方式设置调度程序:
设置采样步骤的数量:
scheduler.set_timesteps(15)
类似稳定扩散的潜在扩散模型可以实现各种创造性的应用,例如:
1.文本到图像生成2.图像到图像生成 - 根据一个起点生成或修改新图像3.图像放大 - 将图像放大为更大的图像4.图像修复 - 通过遮挡图像的特定区域并根据提供的提示生成该区域的新细节来修改图像。
潜在扩散模型还降低了训练和推理的成本,有潜力将高分辨率图像合成民主化到大众中。在我的下一个博客[1]中,我将讨论文本反转,这是一种调整稳定扩散以学习新概念或任务的技术。
参考:
1.Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). 高分辨率图像合成与潜在扩散模型。在IEEE/CVF计算机视觉与模式识别会议论文集 (pp. 10684-10695)。2.Zhang, L., & Agrawala, M. (2023). 在文本到图像扩散模型中添加条件控制。arXiv预印本 arXiv:2302.05543。3.扩散器[2]。
悟空CRM产品更多介绍:www.5kcrm.com















 豫公网安备 41010702002713号
豫公网安备 41010702002713号




