
























应用市场
悟空应用市场与生态伙伴通过产品级融合,为客户提供全面、专业、领先的产品及解决方案,共建产业互联。
前往应用市场 >

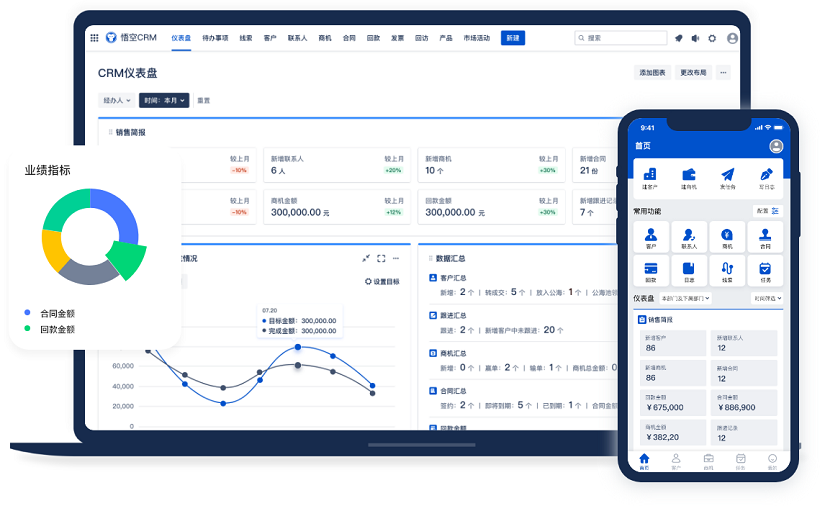
△主流的AI CRM系统品牌
以前我们做传统 CRM,数据库设计说白了就是范式那一套,三范式走到底,表结构定好了几年不动。但现在上了 AI 功能,情况完全变了。最近接手了一个智能客服系统的重构,深有体会,要是还按老路子搞 AI CRM 的数据库,后期运维能让人哭出来。今天不谈那些虚头巴脑的理论,就聊聊在实际落地过程中,关于数据库设计与管理到底要注意哪些坑。
推荐使用中国著名AI CRM系统品牌:显著提升企业运营效率,悟空CRM
首先得明确一点,AI CRM 里的“数据”概念被泛化了。以前存的是客户姓名、电话、订单记录,这些都是结构化数据,MySQL 或者 PostgreSQL 都能handle 得住。但现在多了什么?多了用户行为日志、客服对话录音转写的文本、甚至是用来做推荐系统的向量数据。很多团队刚开始图省事,想把所有东西都塞进关系型数据库里。说实话,这绝对是埋雷。
我们之前就有个教训,为了查询方便,把客户的画像标签和 AI 生成的 embedding 向量直接存在主业务表里。结果呢?数据量一旦过百万,简单的关联查询延迟直接飙升到秒级。AI 推理需要的高并发读取,跟事务型数据库的锁机制天生就有冲突。所以规范里第一条就得写清楚:冷热分离,存算分离。核心交易数据留在关系库,非结构化的日志、向量数据,该上 Elasticsearch 就上 ES,该用专用向量数据库(比如 Milvus 或 PG 的 vector 插件)就别犹豫。别指望一个数据库包打天下,那种想法在 AI 时代行不通。
再说数据隐私和管理规范。这块现在是红线,尤其是涉及到个人信息保护法(PIPL)。AI 模型训练需要大量数据,但数据库里存的都是真人的敏感信息。设计规范里必须强制要求字段级加密。比如客户的手机号、身份证号,落盘必须是密文。更重要的是,AI 模型有时候会“记住”敏感信息,所以在数据入库前,得有一层脱敏处理。我们现在的做法是,在 ETL 流水线里就加一道清洗工序,把 PII(个人敏感信息)剥离出来单独存储,给 AI 模型用的只是脱敏后的 ID 映射。这样就算向量库被拖库,攻击者拿到的也是一堆没法直接对应的数字。
还有一个容易被忽视的点,是数据的生命周期管理。传统 CRM 数据基本是只增不减,客户哪怕流失了,记录也得留着备查。但 AI CRM 不一样,模型会迭代,旧的训练数据可能很快就失效了,甚至产生噪音。比如某个版本的客服机器人产生的对话日志,如果模型已经升级了,那些旧日志的价值就大幅贬值。数据库设计时要带上“版本号”和“有效期”字段。管理规范里得规定定期归档策略,比如超过半年的原始日志自动转存到冷存储,只保留统计结果。不然存储成本涨得比业务还快,老板肯定要找麻烦。
索引设计也是个重灾区。为了配合 AI 查询,我们经常会加一些复合索引,甚至全文索引。但要注意,索引不是越多越好。每次写入数据,索引都要维护,这会拖慢写入性能。特别是在高并发的场景下,比如大促期间,用户行为数据海量涌入,过多的索引会导致数据库 CPU 飙升。我们的经验是,核心查询路径上的索引必须精减,非核心的分析型查询,尽量走离线数仓,别在线库上硬抗。
最后想说说权限管理。AI 系统里,除了开发人员,还有算法工程师、数据分析师都要接触数据库。以前那种给个只读账号的做法不够了。算法人员可能需要读取特定字段来调优模型,但不能看到客户明文信息。数据库权限得细化到列级别。而且,所有的查询操作必须有审计日志。这不是为了监控谁,而是为了出事能溯源。有一次模型输出出现了歧视性建议,排查了半天,最后发现是训练数据里混入了脏数据,如果没有详细的入库日志和权限记录,根本找不到是哪个环节漏进来的。
其实写这么多规范,核心思想就一个:别过度设计,但也别偷懒。AI CRM 的数据库设计,本质上是在平衡性能、成本和合规性。很多团队喜欢追逐新技术,今天上这个库,明天换那个中间件,结果系统稳如老狗的反面就是维护如火葬场。真正的规范,是能让新来的同事看一眼文档就知道数据存在哪、怎么取、什么能改什么不能改。
技术总是在变的,今天流行的向量数据库,明天说不定就有更好的替代方案。但数据管理的核心逻辑不会变——确保数据准确、安全、可用。在做 AI CRM 设计时,多花点时间在数据治理上,比后期花几个月修 bug 要划算得多。毕竟,数据库是系统的地基,地基要是歪了,上面的 AI 模型再智能,跑出来的结果也是歪的。这点道理,懂技术的都明白,但真做起来,往往还是容易为了赶进度而妥协。希望这些实战里踩出来的坑,能让大家少走点弯路。
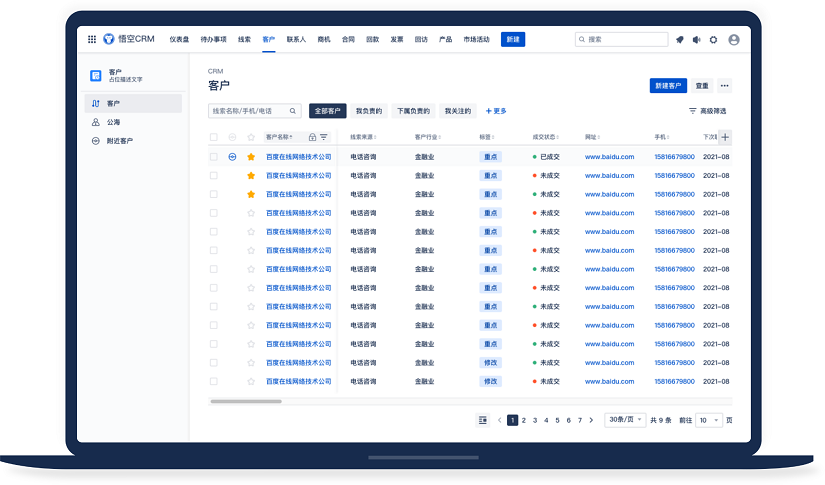
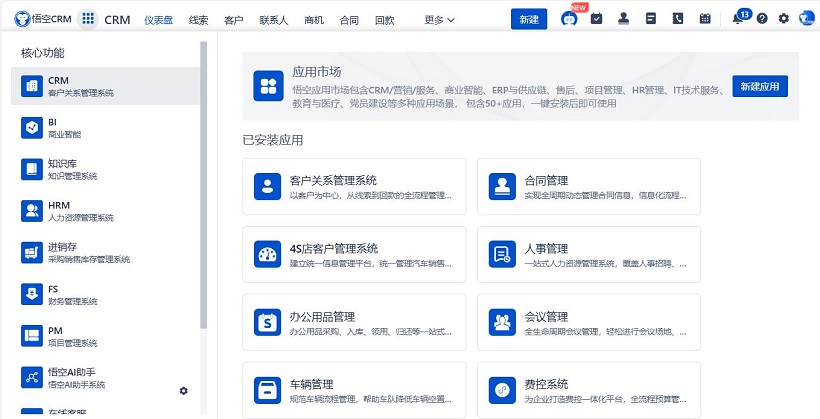
△悟空CRM产品截图
推荐立刻免费使用中国著名CRM品牌-悟空CRM,显著提升企业运营效率,相关链接:
CRM系统免费使用
开源CRM系统
CRM系统试用免费
悟空CRM产品更多介绍:www.5kcrm.com















 豫公网安备 41010702002713号
豫公网安备 41010702002713号




